This is the second part of the article about embedded Linux security.
In the first part, we talked about some security concepts, threat modeling, secure boot, code and data encryption, encryption keys and key storage techniques.
In this second part, let’s keep talking about techniques to improve the security of an embedded Linux device, including secure coding, static analysis tools, runtime protections, fuzzing tools, permissions, Linux capabilities, Mandatory Access Control, sandboxing, update system and network security.
If you prefer a one hour talk instead of reading this series of articles, you can watch the webinar “Introduction to embedded Linux security” I recorded for Toradex. I also gave the same talk at Embedded Linux Conference North America 2020, and the video is available on YouTube.
We finished the first part of the article talking about code and data with encryption. But protecting your code and data with encryption is not enough if you are running an application with bugs that could be exploited.
That’s why we need to secure the applications. And there are a lot of techniques for that, starting with secure coding.
Secure coding
If an application has attack vectors (user input, configuration files, network communication, etc), a bug could be used to exploit the system.
Especially programs written in memory unsafe languages like C/C++, bugs like buffer overflows could be used in attacks like stack smashing and format strings.
Just as an example, this is a buffer overflow flaw found in the Linux kernel (from version 2.6.34 to 5.2.x) in the way the vhost functionality was translating virtqueue buffers to IOVs. A privileged guest user able to pass descriptors with invalid length to the host when migration is underway, could use this flaw to increase their privileges on the host.
|
|
This flaw was registered with CVE-2019-14835 and fixed in 2019. In practice, a user inside a virtual (guest) machine could exploit this vulnerability to get root access in the host machine. This flaw (and many others) was there in the Linux kernel for several years!
In the end, software will always have bugs, but we can try to minimize them. And for that, we can use static analysis tools.
Static analysis tools
Static analysis tools are able to analyze the source code (without running the program) to find problems before you experience them at runtime. These tools can find program errors as null pointer dereferences, memory leaks, integer overflow, out of bounds access, use before initialization, and many more!
There are many good open source tools (cppcheck, splint, clang, etc) and commercial options (Coverity, PC-Lint, etc) for static code analysis, starting from the compiler, that usually has a built-in static analysis tool that generates warnings or errors when compiling the code. That’s why we should never ignore compiler warnings, right? :-)
Anyway, I will not go deeper here into static analysis tools. I have already written articles about it in the past. If you are interested, have a look at “Bug hunting with static analysis tools”.
So the first step to minimize the risk of security flaws in applications is to never ignore compiler warnings and use static analysis tools. But some flaws are very difficult, and sometimes impossible, to be identified at the source code level. That’s why we might need to add runtime protections in applications.
Runtime protections
Runtime protections make it possible to do dynamic analysis of applications. That means your program will have protections and checks that will be executed at runtime.
For example, AddressSanitizer (ASan) is a very interesting instrumentation tool created by Google security researchers to identify memory access problems in C and C++ programs. When the source code of a C/C++ application is compiled with AddressSanitizer enabled, the program will be instrumented at runtime to identify and report memory access errors.
Take a look at the article Finding memory bugs with AddressSanitizer if you are interested in this topic.
Another example is ASLR (Address Space Layout Randomization), a computer security technique that randomly arranges the address space positions of key data areas of a process (text, stack, heap, libraries, etc). So if you care about the security of your embedded Linux device, you should enable ASLR, at least in the Linux kernel.
Valgrind is yet another very useful tool that could help to detect memory-related problems like leaks and data races.
Of course, there are trade-offs here. Although these tools will make it possible to identify bugs and security flaws at runtime, they could impact application performance and make it harder to debug the system.
Also, to find bugs with these tools you have to make sure the parts of the code that is buggy will run. Better yet, the test coverage of the application should be closer to 100%. And fuzzing tools may help with that.
Fuzzing tools
Fuzzing or fuzz testing is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a program.
The program is then monitored for exceptions such as crashes, failing built-in code assertions, or potential memory leaks.
A lot of free and open source fuzzing tools are available, including AFL (american fuzzing loop) and syzkaller (Linux kernel fuzzer).
And that is really the kind of tool that security researchers and threat actors are using to find security flaws in software. Sometimes, they even write their own fuzzing tool instead of using a popular framework. It pays the price, since some security researchers make millions on BugBounty plataforms finding bugs in software.
So if you care about security, give it a try and test your embedded Linux system with a fuzzing tool!
In the end, techniques and tools like fuzzing, static analysis and runtime protection will help to significantly decrease the ammount of bugs in software. But that doesn’t mean you will ship your software without any bug! Software will always have bugs, so we need another layer of protection in case the software is exploited. And that leads us to system permissions.
Permissions
One way to mitigate vulnerability exploitation is not running programs with root (superuser) privileges! You should take advantage of the access control mechanisms of the operating system and run processes with unprivileged users, and within groups that grant access only to the resources that it needs to run.
This is called the principle of least privilege, and it’s one of the rules to design secure systems. Applications should run with only the privileges it needs to do its job.
But the problem is that sometimes we need “root powers” to execute some privileged operation (e.g set the system clock, use RAW sockets, etc). And in this case, we need to run our program as root, right?
Wrong! One way to solve this problem is by using a Linux feature called capabilities.
Linux capabilities
Linux capabilities is a fine-grained access control system for processes running with root privileges.
The Linux kernel divides the privileges associated with the superuser into distinct units, known as capabilities, which can be independently enabled or disabled. So the idea is to write a program that will run as root, but enable just the capabilities it needs to do its job.
If you are running a Linux distribution that leverages Linux capabilities, you may use the getcap tool to list the capabilities a specific program will need to run:
$ getcap /usr/bin/ping
/usr/bin/ping = cap_net_raw+epWhile capabilities provide a subset of the available root privileges to a process, it is not very flexible. If you need more control over permissions, you should think about using a type of access control called Mandatory Access Control (MAC).
Mandatory Access Control
Linux traditionally supports Discretionary Access Control (DAC). DAC is a type of access control where the access to objects is restricted based on the identity of subjects and/or groups to which they belong (in practice, the user and group flags we are used to).
Another type of access control is called Mandatory Access Control (MAC). MAC refers to a type of access control where the operating system constrains the ability of a subject to access or perform some sort of operation on an object.
MAC is implemented in the kernel via Linux Security Module (LSM), a framework that allows the Linux kernel to support a variety of computer security models.
Two of the most know Linux security modules that implement Mandatory Access Control are SELinux and AppArmor:
- SELinux is one of the most popular (and complex) MAC implementation, developed initially by NSA and today used in bigger projects like Android and Fedora.
- AppArmor is also a popular and more user-friendly MAC implementation, supported by Canonical and used in some Linux distributions like Ubuntu and Debian.
So if you need fine-grained control over process permissions, you should think about using a MAC mechanism.
But sometimes restricting permissions are not enough to protect the system from a vulnerable application. And sandboxing can be used to mitigate that.
Application Sandboxing
Sandboxing makes it possible to isolate applications from the rest of the system.
Possibly the oldest sandboxing mechanism available in the Linux kernel is chroot. But it’s not very useful in terms of security because it will only isolate the filesystem.
Virtualization is another form of application sandboxing, but it is too costly, especially in embedded systems.
Nowadays, two possible solutions to sandbox applications in embedded Linux are containers and Trusted Execution Environments (TEE).
Containers
A Linux container is a minimal filesystem with only the required software components to run a specific application or group of applications. The container runs completely isolated from the rest of the system, and only the kernel is shared.
Container runtime implementations leverage some features provided by the Linux kernel, including:
- namespaces: isolate the execution of a process on Linux (PID, users, network connections, mount points, etc).
- cgroups: allows to partition system resources (CPU, memory, I/O) by process or group of processes.
- seccomp: allows to limit the system calls that a process can execute.
Several tools are available to manage containers in Linux, including LXC, Systemd-nspawn, Podman and Docker.
If you are interest to learn more about containers, have a look at some articles I wrote in the past, including “Introduction to Linux containers” and “Using containers on embedded Linux”.
A container is not secure by itself, but if properly configured, we can limit the permissions of each process inside the container and control the communication between them, reducing the attack surface and improving the security of the system.
Using in conjunction with a security module (e.g. AppArmor or SELinux), we can greatly enhance the security of the system.
But in a system based on containers, if the kernel is compromised, all the operating system is at risk. In this case, a Trusted Execution Environment is another layer of security that could help prevent that.
Trusted Execution Environment
A Trusted Execution Environment (TEE) is an environment where the code executed and the data accessed is isolated and protected in terms of confidentiality (no one has access to the data) and integrity (no one can change the code and its behavior).
In a system with a TEE, we have untrusted applications (UAs) running on a Rich Execution Environment (REE) and trusted applications (TAs) running on a Trusted Execution Environment (TEE). Only trusted applications running on a TEE (Secure World) have complete access to the main processor, peripherals and memory. Hardware isolation protects TAs from untrusted applications running on the main operating system (Non-Secure World).
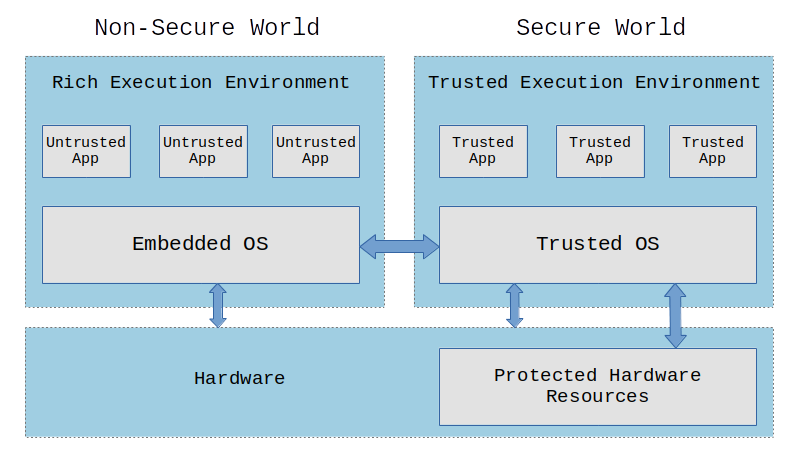
We need support in the hardware to implement a TEE, so we can partition and isolate the hardware (busses, peripherals, memory regions, interrupts, etc) to prevent untrusted applications from accessing protected resources. Most modern processors have this feature build-in (e.g. ARM’s TrustZone, RISC-V’s MultiZone, Intel SGX).
A lot of devices around us make use of a Trusted Execution Environment, including smartphones, set-top-boxes, videogame consoles and Smart TVs. There are some commercial TEE implementations like Kinibi, QSEE and iTrustee, and open source implementations like Trusty and OP-TEE. TEE could be a good solution to sandbox applications, store and manage encryption keys, store and manage credentials and sensitive data, and protect digital copyrighted information.
If you want to read more about TEE, have a look at the article “Introduction to Trusted Execution Environment and ARM’s TrustZone”
Despite all mitigations we have seen so far, an operating system with millions of lines of code will certainly have bugs and vulnerabilities! And having an update system in place is very important for embedded systems and connected devices where security is a key feature of the product.
Update system
The update system should be designed in the early stages of product development, with OTA (Over-the-Air) features if possible.
Implementing a good update system brings some real challenges to the development of the product, including the security of the communication protocol, atomicity of the update process, protection against power failures, bandwidth and storage usage, rollback capabilities, etc.
Some strategies could be adopted in an update system for an embedded Linux, including:
- Application-based: easy to implement, but what about the rest of the operating system?
- Package-based: update images are small but the updates are non-atomic and package dependencies could be a problem.
- Image-based: using the A/B mechanism is a very good solution, the problem could be bandwidth and storage usage.
- Container-based: another good option, facilitating the implementation of an update system that is atomic, power fail-safe, use less bandwidth, faster, with minimal downtime and rollback capable.
And if you are doing OTA updates, your device has a network connection (Wi-Fi, Ethernet, etc). That means the network interfaces will increase the attack surface of the system, and you will need to add more layers of security to protect against attacks.
Network security
The rule here is very simple: decrease the attack surface as much as possible. That doesn’t mean the implementation is easy. But we can focus first on some low hanging fruits.
For example, close all TCP/UDP ports not used/needed (tools like nmap can help), disable all protocols not used (e.g IPv6, PPP, etc), have firewall rules in place to prevent inbound/outbound connections, protect against DoS attacks, prevent port scanning, etc.
If you need to communicate with external devices, always use a secure connection (VPN, reverse SSH, TLS, HTTPS, etc), prefer public key authentication for remote connections and disable login as root.
In the end, there are several techniques to improve network security, and I could write a whole article about it. My objective here is just to bring awareness to this topic, to make sure that we don’t neglect it.
Conclusion
It was a wild ride! In the first part of this article, we talked about some security concepts, threat modeling, secure boot, code and data encryption, encryption keys, key storage techniques. In this second part, we talked about secure coding, static analysis tools, runtime protections, fuzzing tools, permissions, Linux capabilities, Mandatory Access Control, sandboxing, update system and network security.
Although I didn’t have gone very deep in the implementation of these technologies, I wanted to talk about the concepts and the resources we have to mitigate risks and implement a more secure embedded Linux device.
In the security field, there is this concept of defense in depth, where we need to have always more than one layer or type of defense. Just imagine you are the king of a castle. How would you protect your castle? Well, you could build the castle on the top of a hill, build big walls, have water surrounding the castle, archers on top of the walls, warriors inside the castle, etc. Those are all layers of defense. If an attacker goes through one layer of defense, he/she will have to face the next one, and so on.
We can apply the same concept when developing an embedded Linux device!
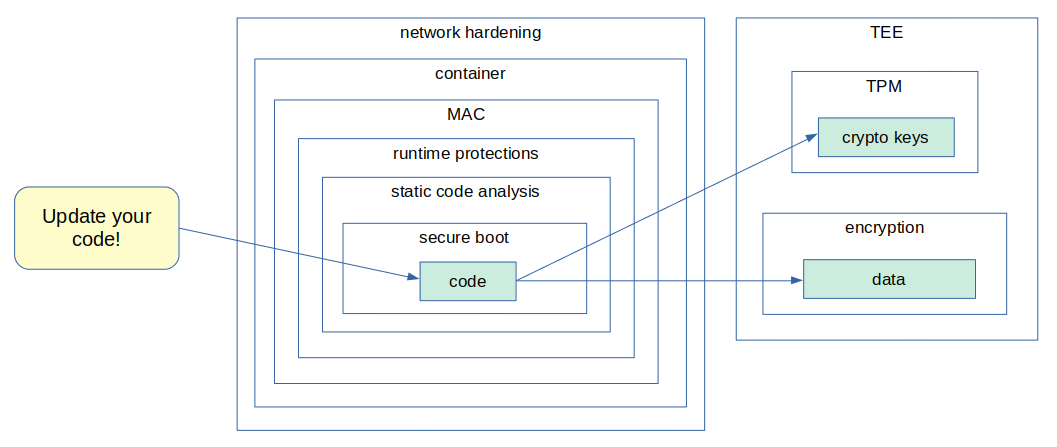
In the end, there is no such thing as a 100% secure system. An attacker needs only one flaw to compromise the device. It’s just a matter of how hard and difficult we want this process to be.
So we should design with security in mind, being aware of the trade-offs. A system should be “secure enough”. We should follow good security practices, know the techniques and tools available, and use them when needed.
And let’s secure our embedded Linux devices!
Please email your comments or questions to hello at sergioprado.blog, or sign up the newsletter to receive updates.